Shall We Dance?
 Holding hands with the agent in the “Shall We Dance?” demonstration
Holding hands with the agent in the “Shall We Dance?” demonstrationRelated Publication
This work will be presented at SIGGRAPH Emerging Technologies 2026 in Los Angeles.
Shall We Dance? Resonance of Intentions with an Embodied Agent based on the Free Energy Principle Takeru Hashimoto, Jun Tani, Shunichi Kasahara SIGGRAPH Emerging Technologies ‘26, Los Angeles, CA, USA, July 19–23, 2026
Overview
Moving together — hand in hand — shapes a profound sense of partnership. In physical joint action we are constantly negotiating intentions: leading, yielding, and adjusting to one another through mutual coordination. This kind of coordination can even push motor performance beyond what either partner could achieve alone.
Most physical agents, however, treat the small frictions of interaction as control errors to be suppressed, and they switch between behaviors using pre-learned transition rules. As a result they cannot respond to a partner’s improvisational moves that happen at arbitrary moments.
Shall We Dance? is an embodied agent grounded in the Free Energy Principle that negotiates intentions through physical contact. Rather than relying on learned switching rules, intention switching here emerges dynamically from real-time prediction-error minimization — so the agent can follow your change of mind from any state, regardless of prior training.
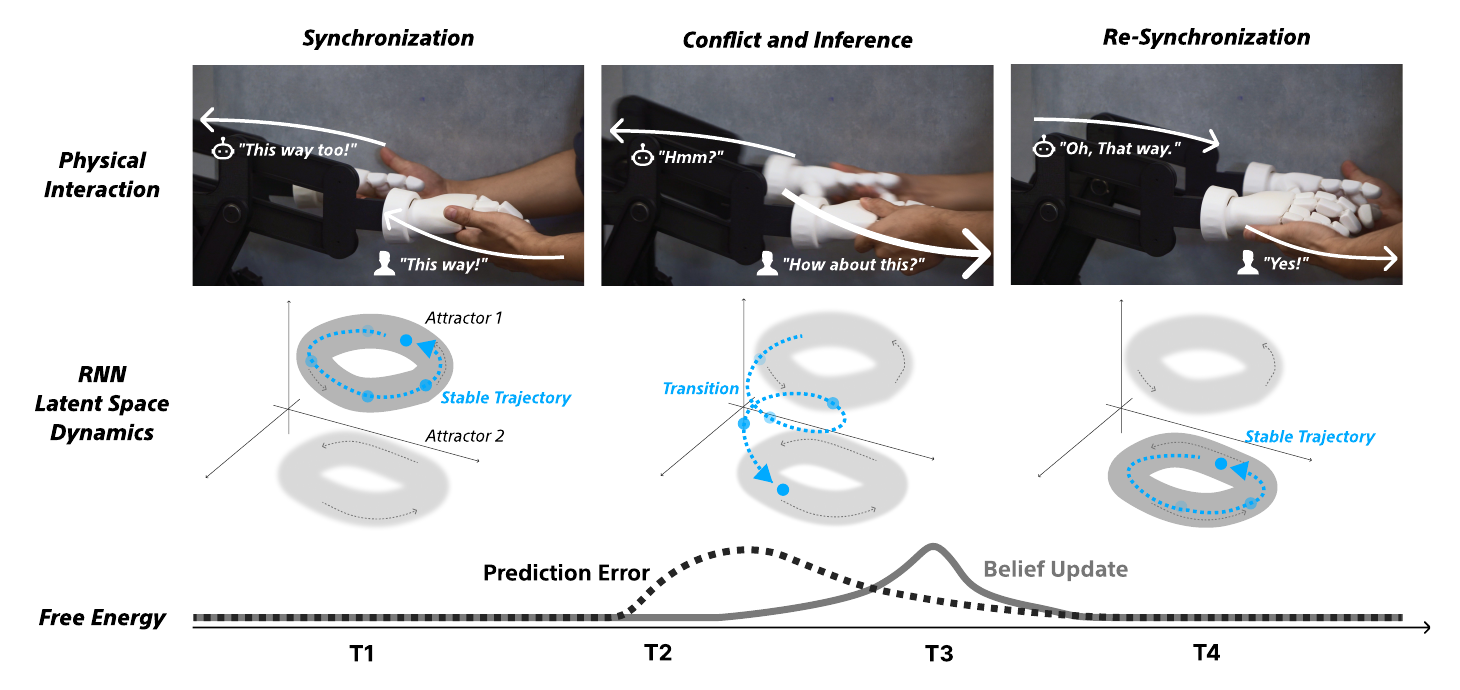
Real-time adaptive coordination via latent attractor dynamics driven by free energy minimization. (T1) Synchronization — partners share a rhythm, a stable limit cycle (Attractor 1). (T2) Conflict — you change your intention and the mismatch spikes the agent’s prediction error. (T3) Inference — to reduce that error the agent updates its belief, driving a transition to a new attractor (1 → 2). (T4) Re-synchronization — the internal state settles into the new attractor and the agent physically adapts to your new intention.
How It Works
Predictive-coding RNN with attractor dynamics
At the core is a continuous-time recurrent neural network (CTRNN) based on predictive coding. Multiple movement patterns are embedded as limit-cycle attractors in a high-dimensional latent space (internal state $\mu_t \in \mathbb{R}^{N}$ , $N = 64$ ). The network is trained to minimize variational free energy, so each learned dance pattern becomes a stable trajectory the agent can fall into.
Real-time negotiation of intention and tempo
During the interaction the model weights are fixed; instead the agent continuously optimizes two internal variables against what it feels from your hands:
- Intention ($\mu$ ) — updating the internal state lets the agent cross from one attractor to another, i.e. change which pattern it intends to perform.
- Tempo ($\tau$ ) — modulating the time constant via a speed ratio lets the agent accelerate or decelerate its own dynamics to match how fast you are moving.
Action–perception loop
Perception and action run as one loop. In perception, the agent updates its internal state to infer your intention; in action, its next-step prediction becomes the target position for a custom 2-DOF force-feedback robot arm. The force fed back through physical contact then updates its belief. The inference loop runs at 30 Hz on a laptop CPU, with motor commands low-pass filtered and sent to the actuators at 100 Hz.
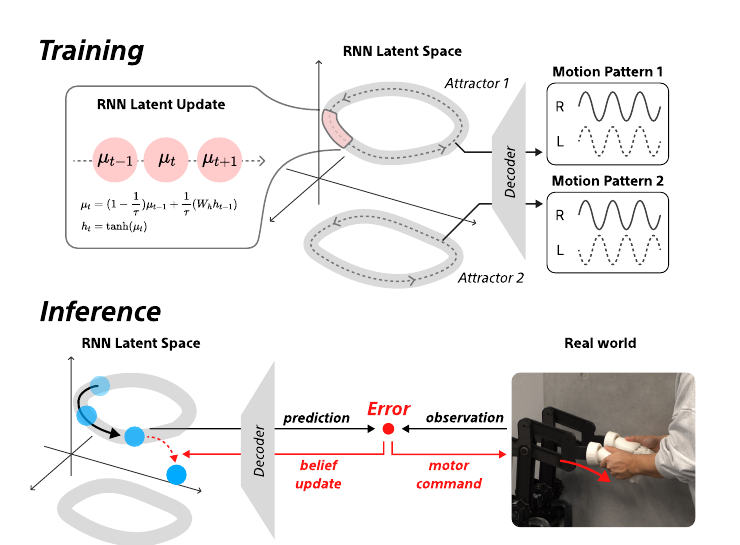
The proposed RNN-based active-inference model. Training: the network learns multiple motion primitives as distinct attractors in the latent space. Inference: a movement gap produces a prediction error that triggers a belief update; by shifting between attractors the agent re-synchronizes in real time.
Demonstration: Shall We Dance?
You grasp the robot’s hand with both of yours and begin to dance. The agent generates one of its learned motion patterns and invites you to follow along. Once you are synchronized, you are encouraged to change the pattern.
At the moment of transition, the agent’s inference process is felt directly through your palms: a stiffening as your intentions diverge, followed by a sudden lightness as the agent grasps your intent. It is a kinesthetic “Yes!” — mutual understanding confirmed through touch alone, without a single word.
Future Work
In the current system both the cognitive and the mechanical impedance of the arm are fixed, so reaction forces persist throughout a transition rather than easing as the agent yields. A natural next step is to dynamically adjust impedance to further minimize free energy. Because changing impedance alters the perceived properties of objects and even one’s own body, incorporating impedance modulation could turn haptic interaction into a channel through which a person reads the agent’s internal state directly.
Poster

Poster presented at SIGGRAPH Emerging Technologies 2026.
Acknowledgments
This work was supported by JST Grant Numbers JPMJCR2552, JPMJPF2205, and JPMJMS2013.