Shall We Dance?
 「Shall We Dance?」の展示でエージェントと手をつなぐ様子
「Shall We Dance?」の展示でエージェントと手をつなぐ様子関連論文
本研究は SIGGRAPH Emerging Technologies 2026(ロサンゼルス)で発表されます。
Shall We Dance? Resonance of Intentions with an Embodied Agent based on the Free Energy Principle Takeru Hashimoto, Jun Tani, Shunichi Kasahara SIGGRAPH Emerging Technologies ‘26, Los Angeles, CA, USA, July 19–23, 2026
概要
手をつないで一緒に動く——その身体的な協調は、深い「パートナーシップ」の感覚を生み出します。私たちは身体的な共同行為のなかで、相手をリードしたり、ゆずったり、互いに合わせたりしながら、絶えず意図を交渉しています。こうした協調は、ときに一人では到達できない運動パフォーマンスをも引き出します。
ところが多くの物理エージェント(ロボットや力覚提示装置)は、こうしたインタラクションのズレを単に抑制すべき制御誤差として扱い、あらかじめ学習した遷移ルールで振る舞いを切り替えます。そのため、任意のタイミングで起こる相手の即興的な働きかけに適応できません。
Shall We Dance? は、自由エネルギー原理に基づき、物理的な接触を通じて意図を交渉する身体エージェントです。学習済みの切り替えルールに頼るのではなく、意図の切り替えがリアルタイムの予測誤差最小化から動的に立ち現れます。これにより、事前学習に縛られることなく、どの状態からでも相手の「心変わり」に追従できます。
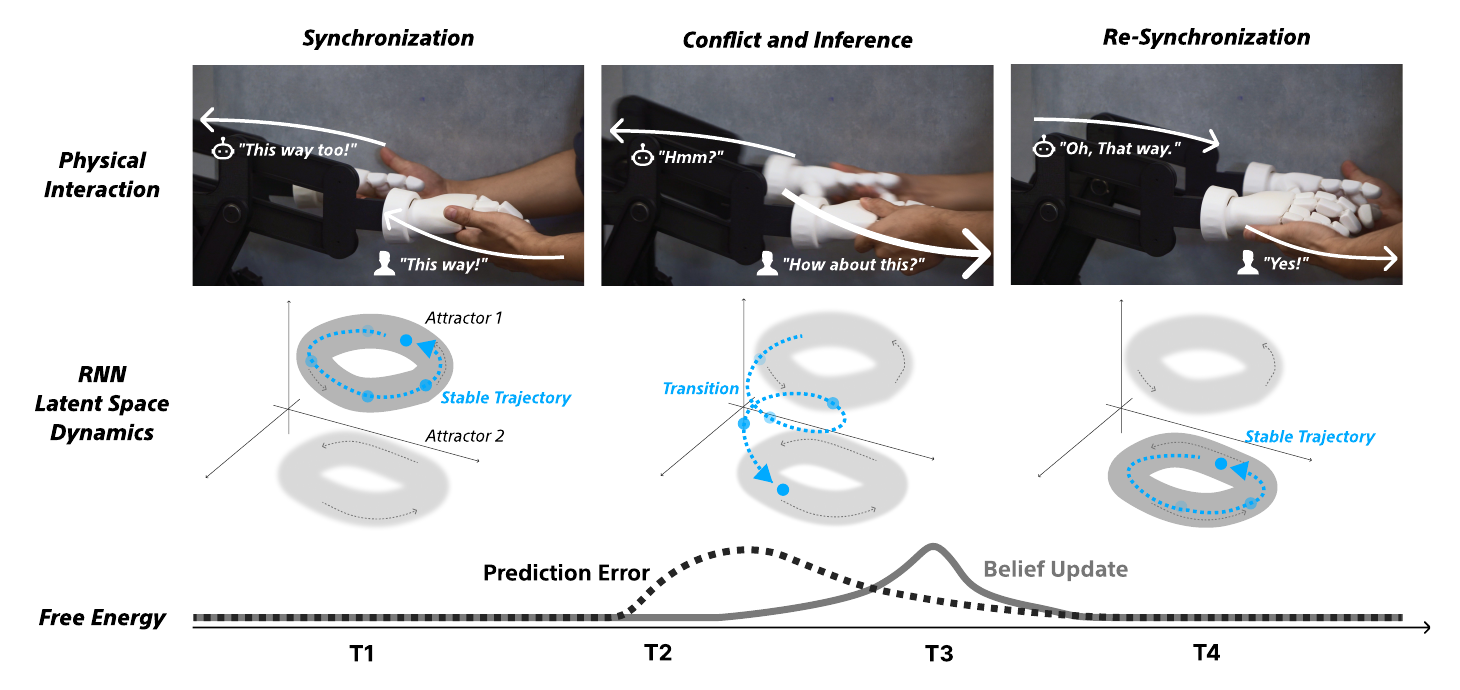
自由エネルギー最小化が駆動する潜在アトラクタ・ダイナミクスによる、リアルタイム適応的協調。(T1) 同期:パートナーはリズムを共有し、安定なリミットサイクル(アトラクタ1)上にいる。(T2) 衝突:あなたが意図を変えると、ズレがエージェントの予測誤差を跳ね上げる。(T3) 推論:その誤差を減らすためにエージェントは信念を更新し、新しいアトラクタへの遷移(1→2)が起こる。(T4) 再同期:内部状態が新しいアトラクタに落ち着き、あなたの新しい意図に物理的に適応する。
仕組み
アトラクタ・ダイナミクスを持つ予測符号化RNN
中核となるのは、予測符号化(predictive coding)に基づく連続時間リカレントニューラルネット(CTRNN)です。複数の動きのパターンを、高次元の潜在空間におけるリミットサイクル・アトラクタとして埋め込みます(内部状態 $\mu_t \in \mathbb{R}^{N}$ 、$N = 64$ )。ネットワークは変分自由エネルギーを最小化するよう学習され、学習した各ダンスパターンはエージェントが落ち込める安定な軌道になります。
意図とテンポのリアルタイム交渉
インタラクション中、ネットワークの重みは固定したまま、エージェントは手から感じる力に対して2つの内部変数を絶えず最適化します。
- 意図($\mu$ ):内部状態を更新することで、あるアトラクタから別のアトラクタへ乗り移る。つまりどのパターンを実行しようとするかを変える。
- テンポ($\tau$ ):速度比を介して時定数を変調し、自身のダイナミクスを加速・減速させて、相手がどれだけ速く動いているかに合わせる。
行為-知覚ループ
知覚と行為はひとつのループとして回ります。知覚では、エージェントは内部状態を更新して相手の意図を推論します。行為では、その1ステップ先の予測を目標位置として、自作の2自由度フォースフィードバック・ロボットアームへ運動指令を送ります。物理接触を通じて返ってくる力が、ふたたび信念を更新します。推論ループはノートPCのCPU上で 30 Hz、運動指令はローパスフィルタを通して 100 Hz でアクチュエータに送られます。
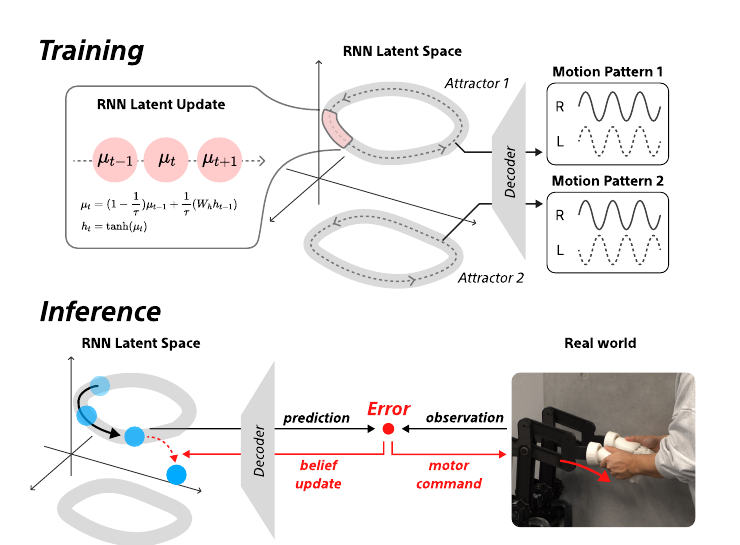
提案するRNNベースの能動的推論モデル。学習:ネットワークは複数の運動プリミティブを潜在空間内の別個のアトラクタとして学習する。推論:動きのズレが予測誤差を生み、信念更新を引き起こす。アトラクタ間を移ることでエージェントはリアルタイムに再同期する。
展示:Shall We Dance?
「こっち!」「ん?あ〜そっちね」——手の力だけで交わす、無言の会話。来場者は両手でロボットの手を握り、一緒に踊り始めます。エージェントは学習した動きのパターンのひとつを生成し、それに合わせるよう来場者を誘います。同期したら、今度は来場者がパターンを変えてみます。
その遷移の瞬間、エージェントの推論プロセスが手のひらを通して直接感じられます。意図がすれ違うときのこわばり、そしてエージェントがあなたの意図をつかんだ瞬間のふっと軽くなる感覚。それは身体で交わす「Yes!」——ひと言も発することなく、触覚だけで成立する相互理解です。
今後の展望
現在のシステムでは、アームの認知的インピーダンスと機械的インピーダンスがどちらも固定されています。そのため、意図の衝突から次の安定状態へ遷移する間も反力が残り続け、相手にゆずる際に力がふっと抜けることはありません。今後の方向性は、自由エネルギーをさらに最小化するようにインピーダンスを動的に調整することです。インピーダンスの変化は物体や自分自身の身体の知覚特性をも変えるため、これを能動的推論の枠組みに取り込めば、力覚インタラクションそのものが、相手(エージェント)の内部状態を直接読み取る「通信路」になりうると考えています。
ポスター

SIGGRAPH Emerging Technologies 2026 で発表したポスター
謝辞
本研究は JST(JPMJCR2552、JPMJPF2205、JPMJMS2013)の支援を受けました。